Глобальный тренд в SEO — поведенческие факторы. Их снова крутят (о Боже, Яндекс, сделай, что-нибудь!), о них спорят и они действительно работают. Показатель, с которого начинаются поведенческие — CTR. Ниже рассмотрим, как увеличить органическую кликабельность, используя структурированные данные.
CTR (click-through rate или кликабельность) — соотношение числа кликов к количеству показов сайта по запросу в выдаче поисковых систем, выраженное в процентах.
Основные типы структурированных данных
Структурированные данные — формат кода, который используется для разметки различных типов информации на наших сайтах. Благодаря им поисковые системы лучше понимают тип контента и:
-
подтягивают в сниппеты дополнительные фрагменты, делая их привлекательнее и информативнее для пользователей;
-
добавляют сайт в различные блоки на выдаче: карусели, граф знаний, рецепты, инструкции и так далее.
Словарей для разметки много, но чаще всего используются:
-
Микроразметка Schema.org. Стандарт, который прекрасно понимает как Google, так и Яндекс.
Ниже пример сниппета страницы, на которой правильно используется словарь schema.org/Recipe. Размечен каждый элемент рецепта: от картинок до ингредиентов. Результат:
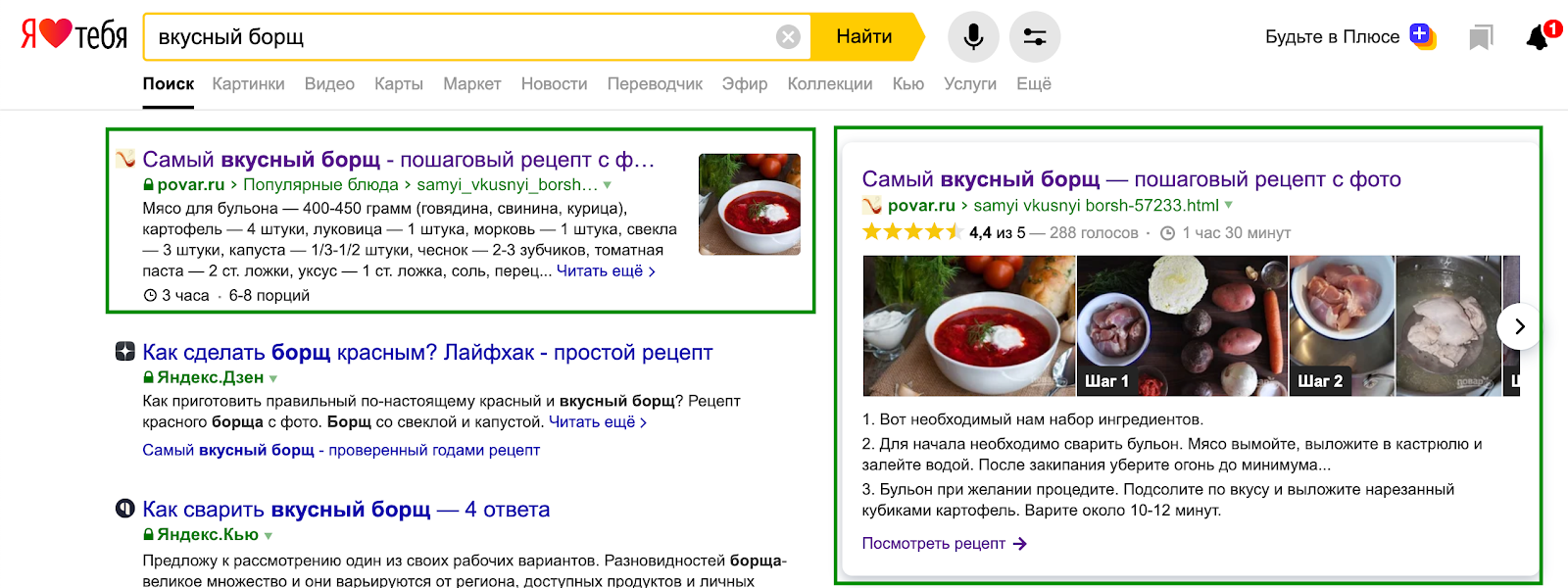
В коде страницы разметка для ингредиентов выглядит так:

Но к правилам оформления мы ещё вернёмся.
-
Open Graph — протокол, разработанный Facebook для формирования превью при шеринге репостов с сайтов в социальных сетях (FB, ВК, Twitter, LinkedIn, Pinterest).
Форматы и синтаксис
Разметка добавляется в HTML-код страницы, поэтому способы могут быть разными. Основные:
-
Microdata — для обозначения элементов на странице используется атрибуты itemprop и itemtype. Громоздко, но просто и понятно как Google, так и Яндексу.
-
JSON-LD — структурированное описание контента размещается с помощью тега <script> в заголовке <head> или теле <body> страницы. Код может подтягиваться динамически, поэтому есть много плагинов под различные CMS для автоматизации разметки. Этот формат особенно приветствуются Google, но пока не поддерживается Яндексом.
-
RDFa — встречается всё реже. Также, как и в microdata, используются атрибуты для разметки видимых для пользователей HTML-элементов: property и typeof.
Microdata
Начнём с самого распространенного формата в рунете. Ключевой момент для понимания: используя Schema.org, независимо от выбранного синтаксиса, мы работаем с сущностями и их свойствами. Правильно определив сущность, можно найти подходящий словарь и схему на любую тематику.
Вот основные типы сущностей, которые поддерживаются поисковыми системами и полезны в SEO:

Например, для разметки информации об организации сначала нужно объявить подходящую схему и словарь с помощью атрибута itemtype:
<div itemscope itemtype="http://schema.org/Organization" > ... </div>
Далее можно использовать различные свойства из указанного словаря и размечать элементы на страницы. Полный перечень свойств каждого словаря можно найти в соответствующих разделах сайта schema.org. Например, адрес:
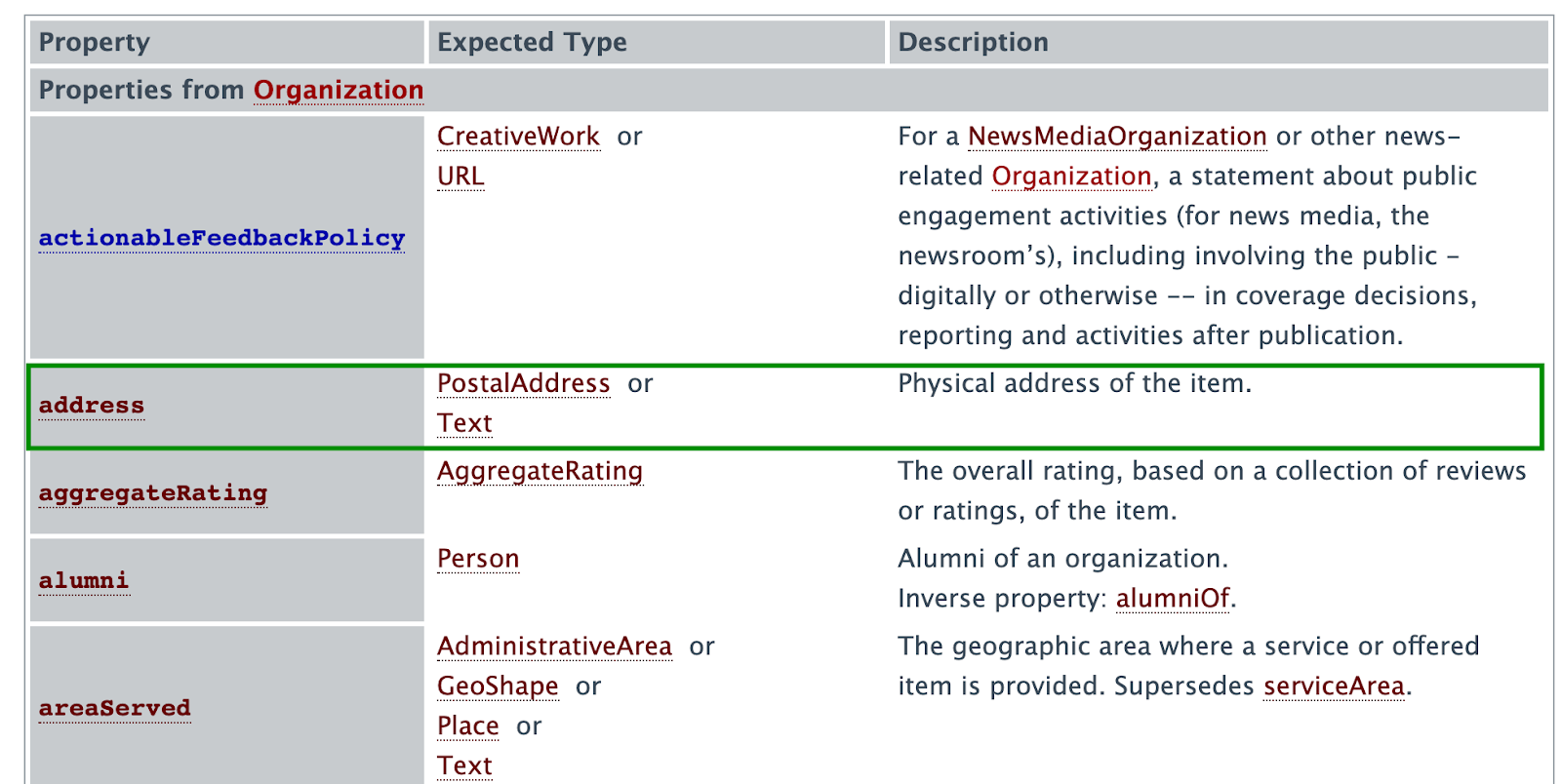
Используем itemprop, в значении которого используется свойство streetAddress, чтобы разметить часть текста, указывающего месторасположение организации:
<span itemprop="streetAddress">Москва, ул. Орджоникидзе, 16</span>
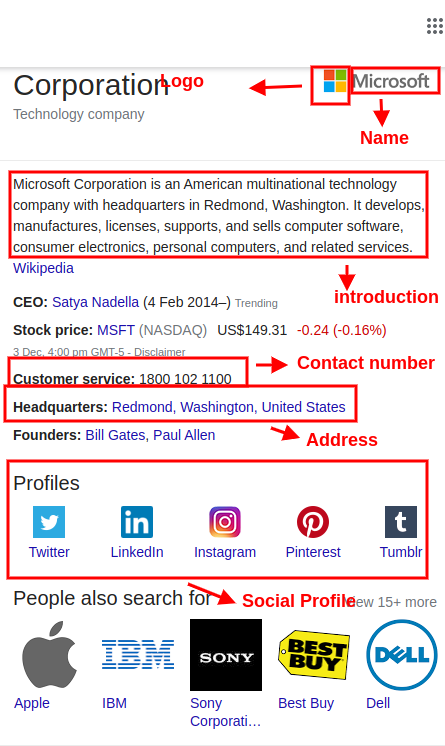
Таким образом, мы сообщаем поисковым системам дополнительные маркеры: вот здесь у нас название организации, здесь логотип, телефон и так далее. Логика простая, а результаты могут иметь приятные последствия в выдаче по витальным запросам. Например подробная информация о компании в Google Knowledge Graph:
Хлебные крошки
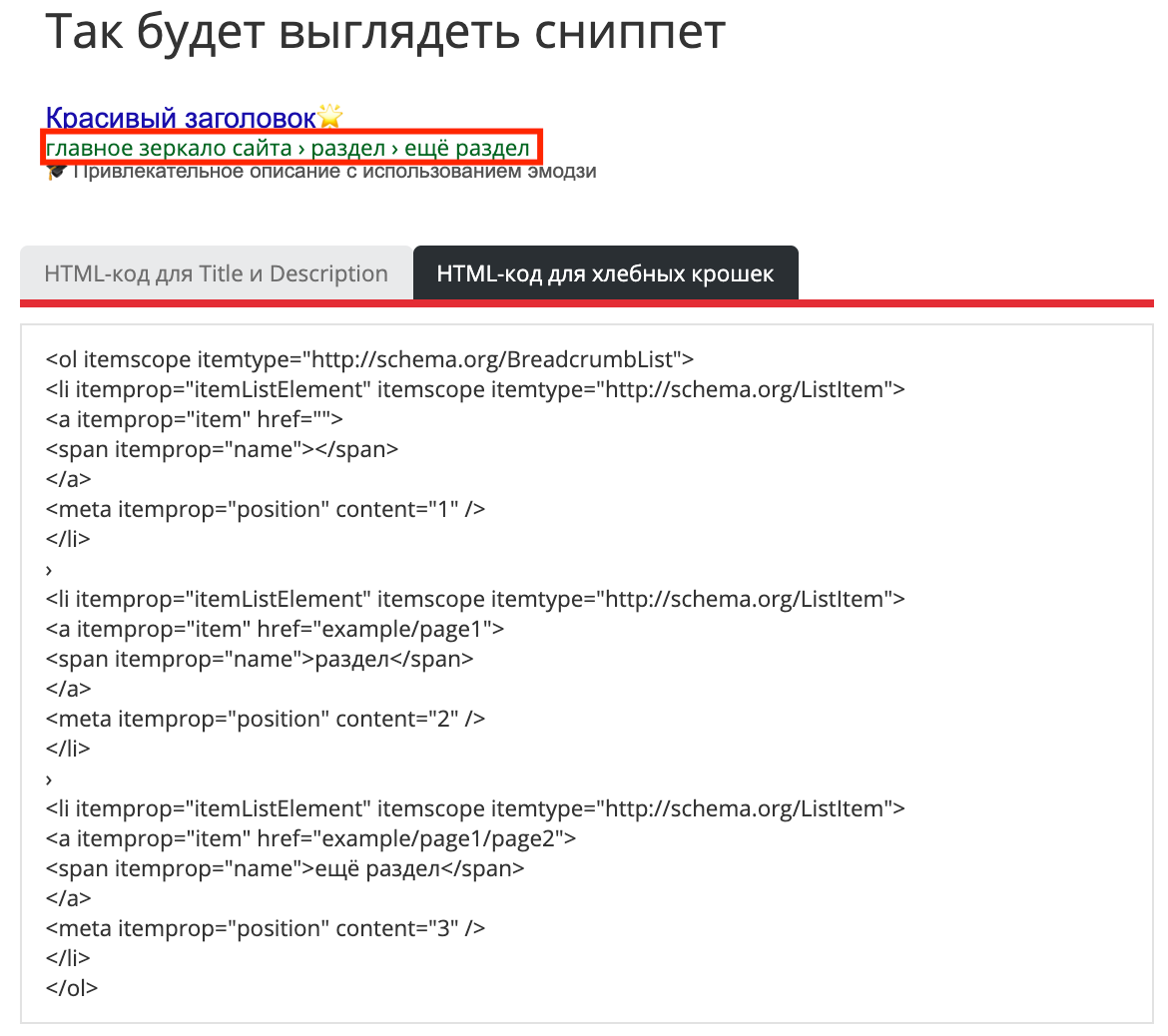
Отдельный словарь, который используется для разметки навигационных ссылок — http://schema.org/BreadcrumbList. Благодаря его использованию в сниппет подтягивается цепочка разделов сайта, что помогает пользователю ориентироваться и подчеркнуть соответствие интенту запроса.

Процесс разметки можно автоматизировать с помощью бесплатного инструмента, который генерирует готовый HTML-код с использованием microdata и возможностью добавить эмодзи в Title/Description.
Полезные и часто используемые словари
JSON-LD
Ещё один способ обозначить элементы на странице и структурировать данные с помощью Schema.org. Напомним, что Джон Мюллер из Google рекомендует использовать именно этот синтаксис, но для Яндекса пока стоит использовать microdata.
Как правило, JSON-объект подключается с помощью тега <script> в заголовок страницы, но можно размещать и в рамках тега <body>. Например, для хлебных крошек код будет выглядеть так:
<html> <head> <title>The title of the page</title> <script type="application/ld+json"> { "@context": "https://schema.org", "@type": "BreadcrumbList", "itemListElement": [{ "@type": "ListItem", "position": 1, "name": "Books", "item": "https://example.com/books" },{ "@type": "ListItem", "position": 2, "name": "Authors", "item": "https://example.com/books/authors" },{ "@type": "ListItem", "position": 3, "name": "Ann Leckie", "item": "https://example.com/books/authors/annleckie" },{ "@type": "ListItem", "position": 4, "name": "Ancillary Justice", "item": "https://example.com/books/authors/ancillaryjustice" }] } </script> </head> <body> </body> </html> Где:
-
"@context": "https://schema.org" — объявление используемой схемы.
-
"@type": "BreadcrumbList" — сущность, которая в примере выполняет роль контейнера.
-
"itemListElement" — массив, который включает в себя отдельные элементы-разделы, то есть хлебные крошки с указанием очередности, анкора и ссылки.
Ниже пример кода для разметки карточки товара, с использование дополнительных сущностей и свойств: от нескольких изображений, до отзыва, рейтинга, цены и наличия.
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Product", "name": "Executive Anvil", "image": [ "https://example.com/photos/1x1/photo.jpg", "https://example.com/photos/4x3/photo.jpg", "https://example.com/photos/16x9/photo.jpg" ], "description": "Sleeker than ACME's Classic Anvil, the Executive Anvil is perfect for the business traveler looking for something to drop from a height.", "sku": "0446310786", "mpn": "925872", "brand": { "@type": "Thing", "name": "ACME" }, "review": { "@type": "Review", "reviewRating": { "@type": "Rating", "ratingValue": "4", "bestRating": "5" }, "author": { "@type": "Person", "name": "Fred Benson" } }, "aggregateRating": { "@type": "AggregateRating", "ratingValue": "4.4", "reviewCount": "89" }, "offers": { "@type": "Offer", "url": "https://example.com/anvil", "priceCurrency": "USD", "price": "119.99", "priceValidUntil": "2020-11-05", "itemCondition": "https://schema.org/UsedCondition", "availability": "https://schema.org/InStock", "seller": { "@type": "Organization", "name": "Executive Objects" } } } </script> В SERP Google результат может выглядеть так:

В выдаче по картинкам также подтянется рейтинг, цена, навигация и описание:
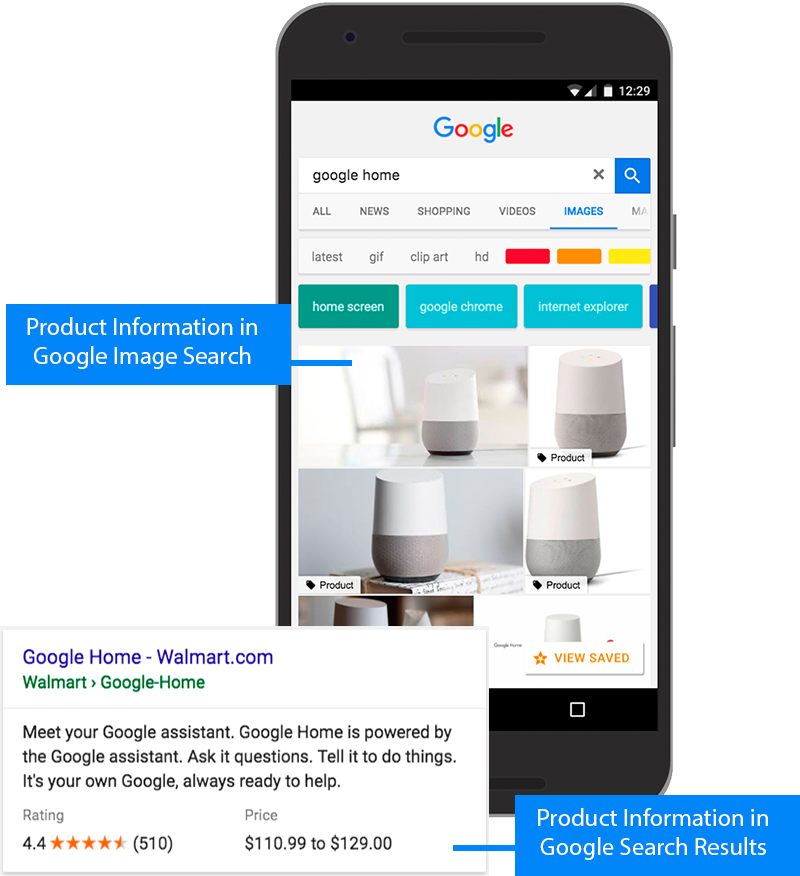
Также для витальных запросов полезно добавить разметку для поиска по сайту прямо в SERP:
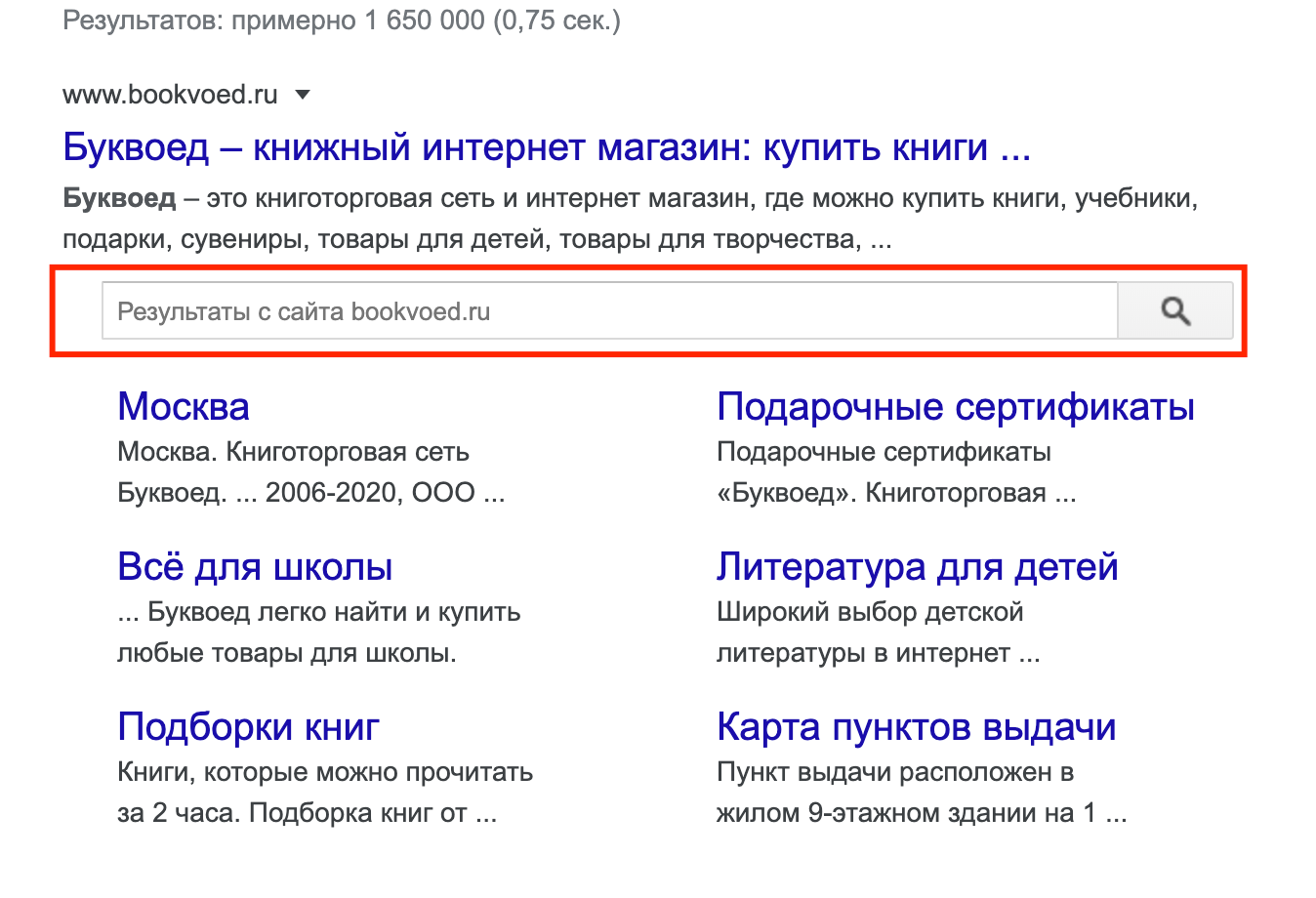
Такой поиск работает как оператор site:www.bookvoed.ru и покажет релевантные результаты также в выдаче Google. Реализуется с помощью сущности SearchAction. В случае JSON-LD можно использовать такой шаблон:
<script type="application/ld+json"> { "@context": "http://schema.org", "@type": "WebSite", "url": "http://example.com/", "potentialAction": { "@type": "SearchAction", "target": "http://example.com/search?&q={query}", "query": "required" } } </script> Важное правило при использовании JSON-LD: все элементы, которые добавляются в код разметки, должны быть доступны и видны пользователям:
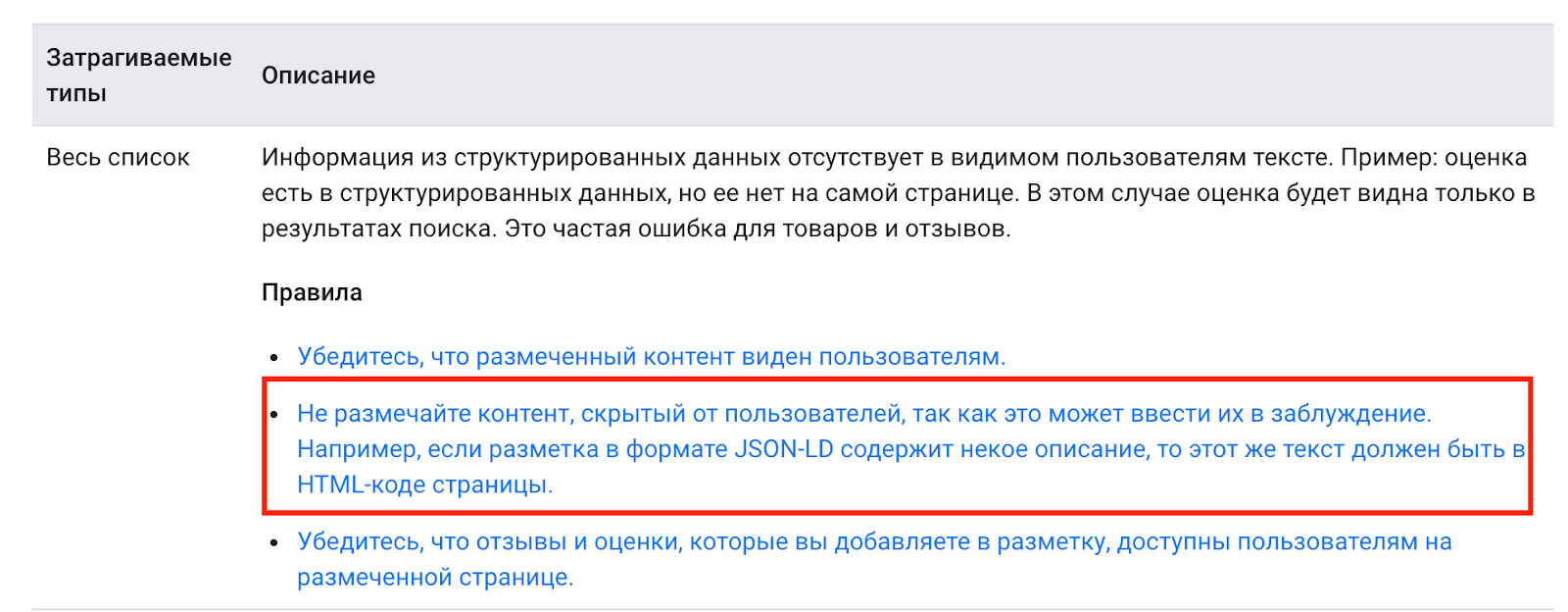
Разумеется, ручная разметка рискует превратиться в раздражающую рутину, поэтому на помощь приходят плагины под популярные CMS и инструменты. Например:
-
Мастер разметки структурированных данных от Google
Популярные плагины под WordPress и Битрикс:
RDFa и RDFa Lite
RDFa — старая и довольно сложная модель представления данных, которая отчасти послужила причиной внедрения новых стандартов попроще, как microdata, так и JSON-LD.
Тем не менее, есть «облегчённая» версия RDFa Lite, которая оперирует пятью основными атрибутами:
-
vocab — указывает на словарь (как правило Schema.org)
-
typeof —определяет описываемую сущность, например Article (статья).
-
property — свойство объекта.
-
resource — идентификатор для каждого описываемого объекта.
-
prefix — служит для объединения нескольких словарей для одного объекта.
Пример использования всех атрибутов:
<body vocab="http://schema.org/"> ... <div property="breadcrumb"> <a href="http://www.ibm.com/developerworks/">IBM developerWorks</a> > <a href="http://www.ibm.com/developerworks/web/">Web development</a> > <a href="http://www.ibm.com/developerworks/views/web/library.jsp" >Technical library</a> </div> <div typeof="Article"> <div property="name">Введение в RDF</div> <p property="author" resource="#uche.ogbuji" typeof="Person"> by <span property="name">Uche Ogbuji</span>, <span property="jobTitle">Партнёр</span>, <span property="worksFor">Zepheira</span>. </p> <div>Published: <span property="datePublished">01 Dec 2000</span></div> <div property="description"> <b>Аннотация</b>: статья о формате Resource Description Framework (RDF), разработанном W3C. </div> <div>Теги для статьи: <span property="keywords">Введение в rdf</span>, <span property="keywords">rdf</span>, <span property="keywords">Руководство</span> .</div> <div prefix="fben: http://www.freebase.com"> Статья предназначена для широкой аудитории. </div> </div> ... </body>
Open Graph
Микроразметка, которая используется для представления сайта при размещении ссылки на него в социальных сетях.
Типичный код выглядит так:

То есть через атрибуты property тега <meta> объявляются свойства: название, изображение, размеры картинок (для разных социальных сетей могут отличаться), описание и так далее. Полный перечень возможных атрибутов можно увидеть на официальном сайте протокола.
Для валидации разметки стоит использовать инструмент Facebook, как разработчиков протокола Open Graph, но можно попробовать и Яндекс.Вебмастер.
Валидаторы микроразметки
Два основных инструмента для проверки корректности структурированных данных:
-
Яндекс.Вебмастер. Умеет проверять microdata, schema.org, микроформаты, OpenGraph, RDFa как для всей страницы, так и для отдельных фрагментов кода.
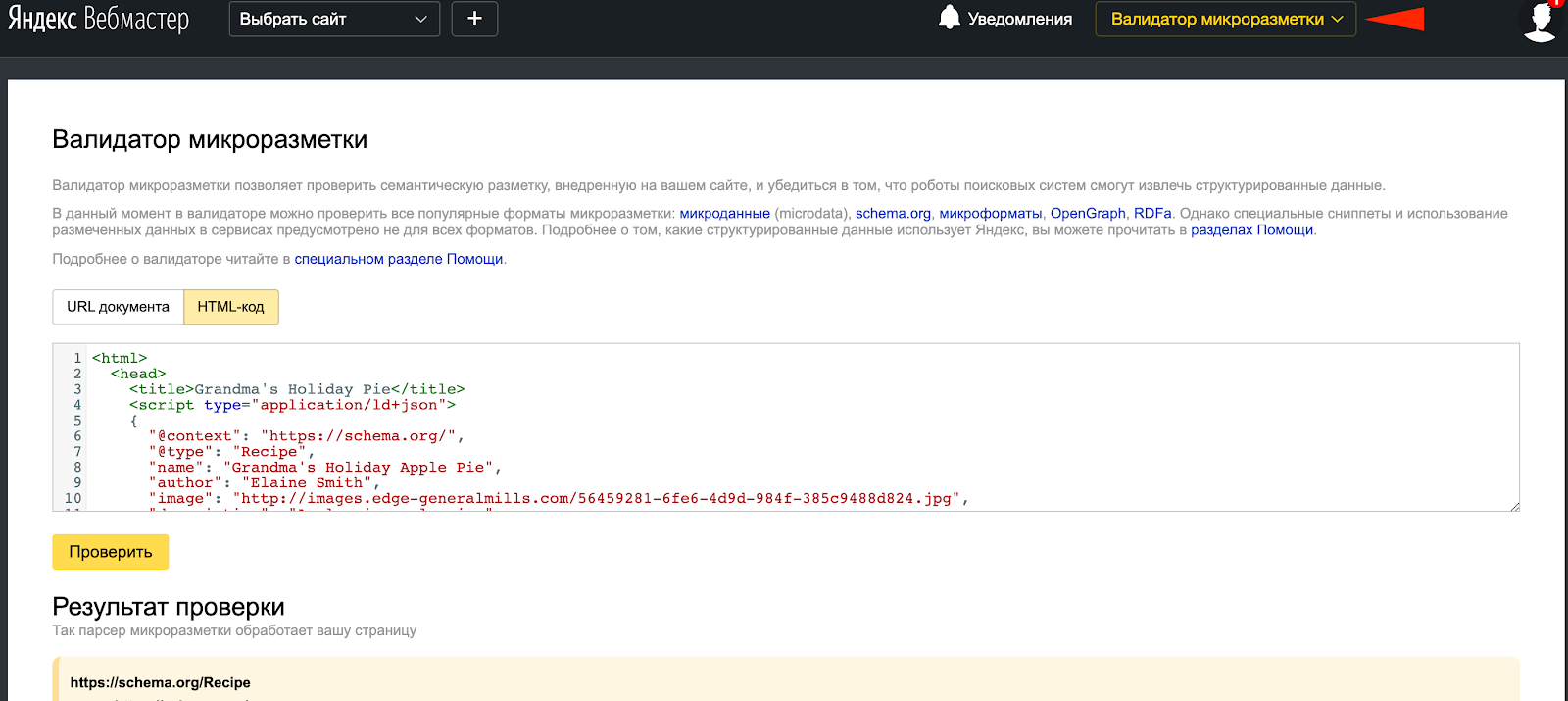
-
Валидатор микроразметки от Google. Есть возможность посмотреть предварительный результат разметки (например, для карточек товаров) и отследить все допущенные ошибки:
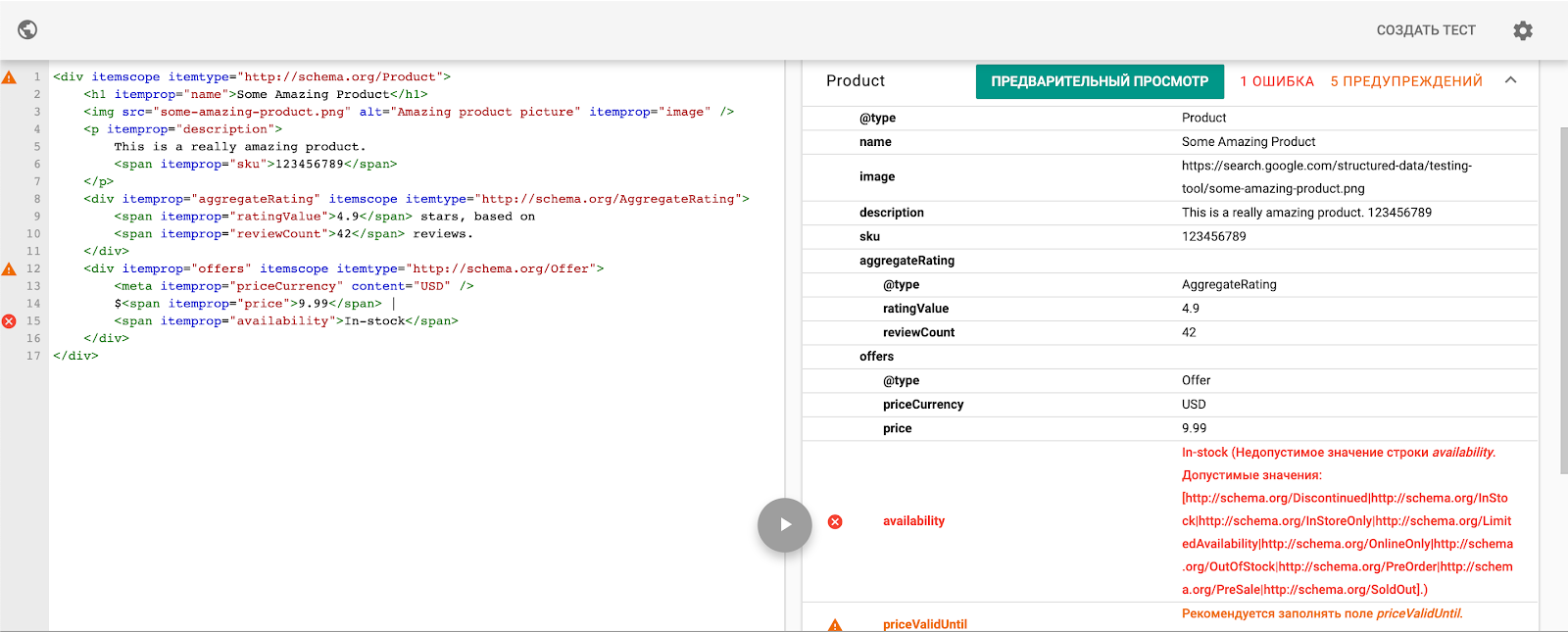
-
Проверка поддержки расширенных результатов в Google. Учитывает только разметку, способную влиять на представление сниппета в выдаче.
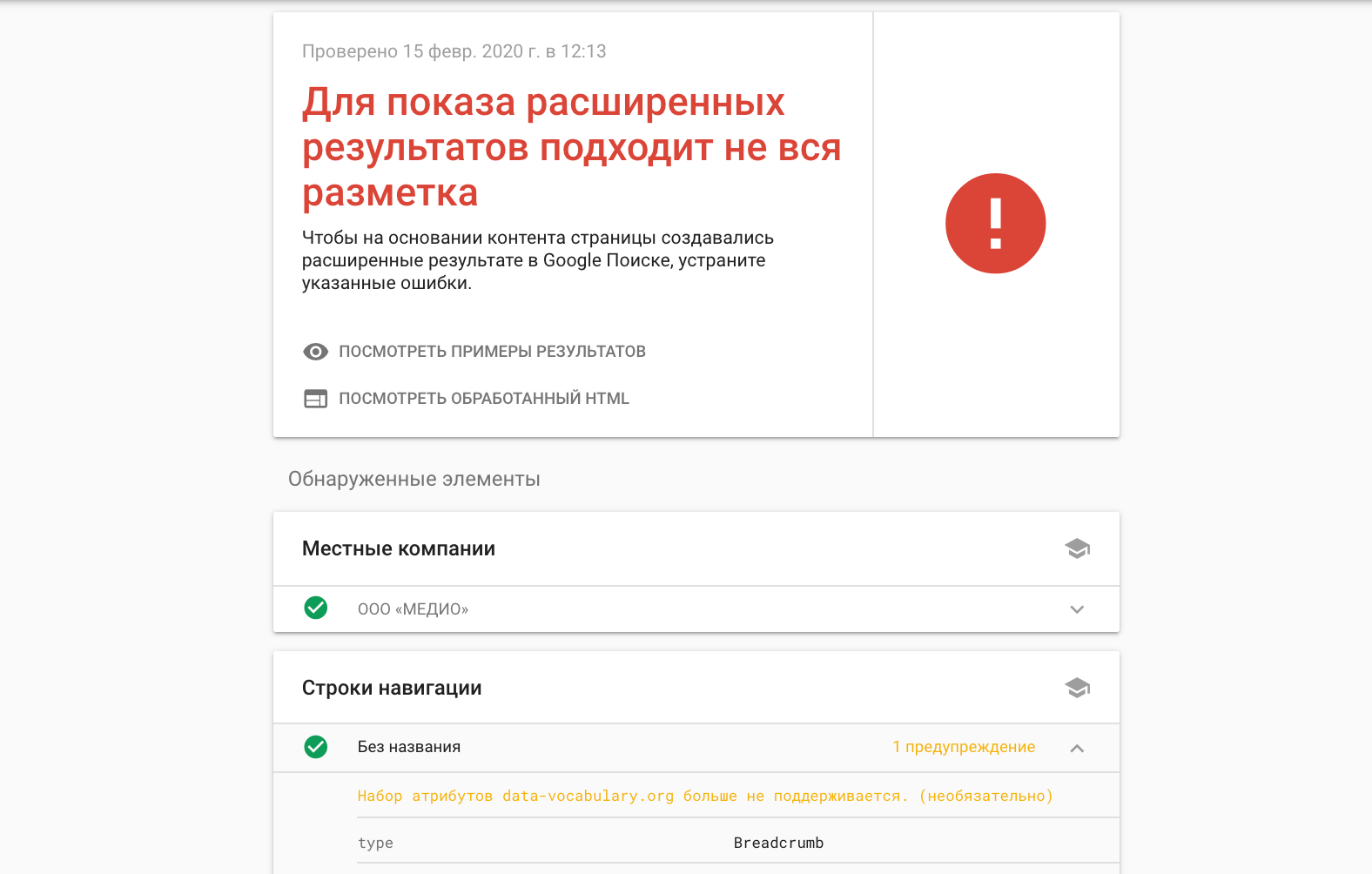
К сожалению, внедрение одной лишь разметки не гарантирует попадания в расширенные сниппеты, но если проект уже в ТОП-3 Google, то рекомендуем изучить все виды расширенных результатов, поддерживаемых Google и начать работать над подходящими под вашу тематику.
Как анализировать результаты?
В «Пиксель Тулс» есть инструменты для оценки поведенческих (под Яндекс и под Google), которые проверяют:
-
Общий трафик на страницу.
-
Общий поисковый трафик.
-
Поисковый трафик по целевому запросу.
-
Долю длинных сессий (более минуты).
-
Среднее время сессий.
-
Долю сессий с глубиной просмотра более двух страниц.
-
Вхождения запроса в Title и/или Description
-
Размер сниппета в сравнении с конкурентами.
Анализировать показатели можно для десктопной, так и для мобильной выдачи.
Также пригодится парсер сниппетов конкурентов: покажет размер заголовков/описаний в символах, эмодзи, наличие вхождения ключевой фразы.
Напоследок посмотрите вдохновляющую динамику CTR при изменении позиций в Google:
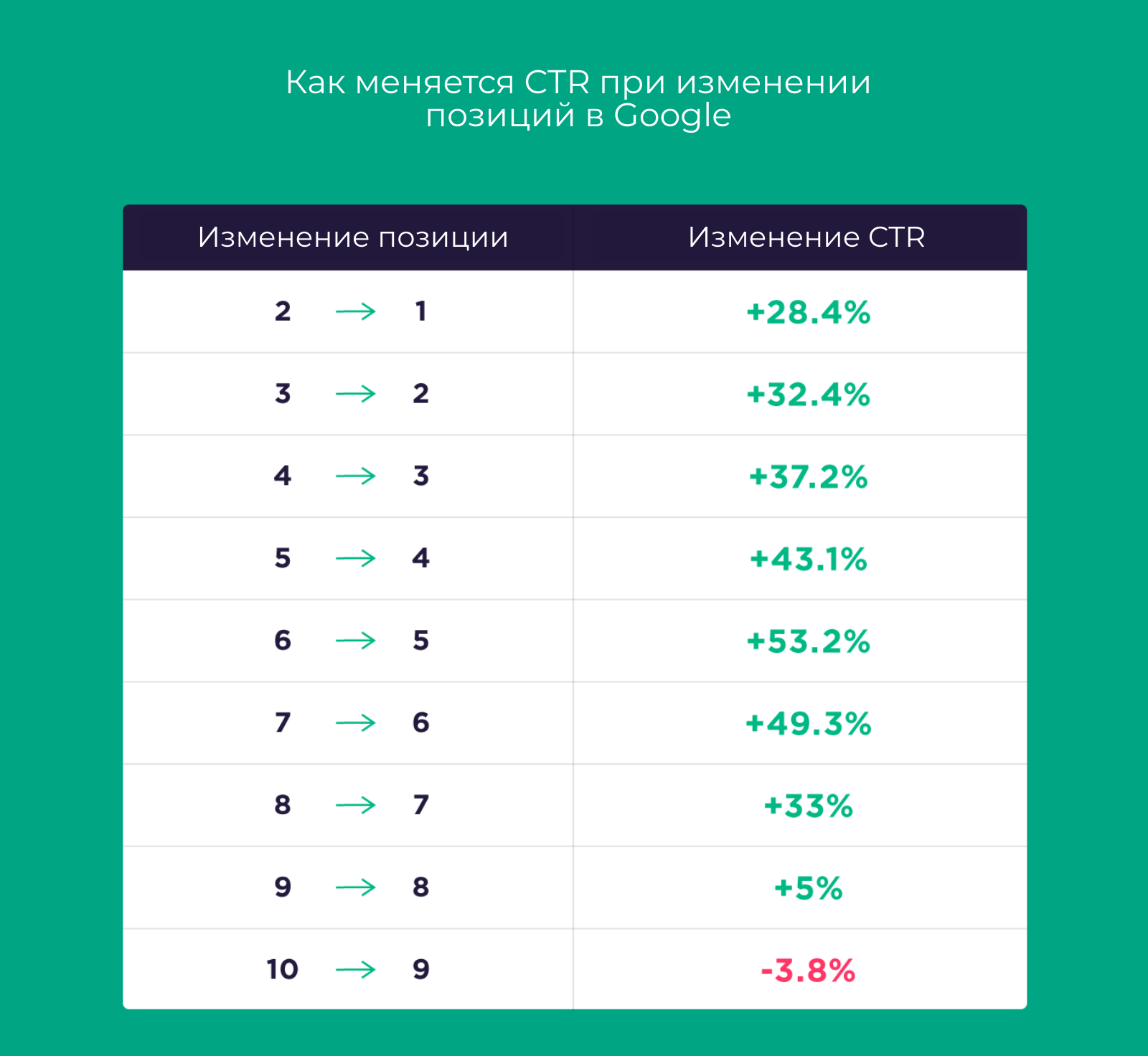
Всем роста и больше переходов из SERP!