Рядовой пользователь поисковых систем редко использует расширенный поиск. А как часто его используют более продвинутые пользователи или специалисты? Ведь очень много «интересных» поисковых операторов, которые позволяют взглянуть на сайт или выдачу с «обратной» стороны.
Вопрос на самом деле интересный. Сейчас большинство операторов зашито в различные плагины и тулбары (тот же RDS bar) и доступны по нажатию одной кнопки. Но знать их и уметь пользоваться – необходимо!
Ведь «по кнопке» есть далеко не все операторы, а некоторые из них оказывают весомую поддержку в диагностике и исследовании сайтов или тематик.
Все операторы описаны в хелпах поисковых систем. Я же хочу пробежаться с вами по основным из них, которые могут прямо сейчас пригодится любому оптимизатору.
FAQ по основным операторам Яндекса
site:
Помогает сделать поиск только по конкретному хосту. Не важно, вводите вы www или нет, поиск будет вестись по всему сайту, включая поддомены.
Чтобы исключить поддомены, нужно использовать следующий оператор
host:
Вы найдете информацию по конкретному сайту, но без субдоменов.
Важно понимать разницу между этими двумя операторами. Если вы используете RDS bar и видите в результатах поиска большую разницу в количестве проиндексированных Гуглом и Яндексом страниц одного и того же сайта, проверьте, включены ли в поиск по Яндексу субдомены при помощи оператораsite: или исключены при помощи host:
url:
C заданным именем хоста этот оператор будет соответствовать предыдущему оператору host:. Он нужен для того, чтобы проверить количество страниц в индексе для того или иного сайта. Проверить индексацию сайта можно также по определенной категории, например:
путеводитель url:www.lonelyplanet.ru/books/*
так мы можем узнать, сколько раз попадается в индексе слово путеводитель из категории books данного сайта.
inurl:
Очень удобен этот оператор, с помощью которого можно проверить, насколько часто встречается какой-либо фрагмент, который вы использовали или хотите использовать в url. Для этого вводим вот такой запрос
путеводитель inurl:books
и получаем только те документы, в url которых встречается слово books.
Построить идентификатор текстовых апдейтов, проверять дату документов и отсеивать быстроробота поможет оператор
date:
Задайте дату в формате:
прививки от гриппа date:20141010
И получите наиболеерелевантные результаты. Особенно удобен этот оператор, если искомые слова относятся к каким-то сезонным предложениям или ежегодным событиям.
Хотите найти документы с заданным тайтлом? Здесь поможет оператор
title:
который будет полезен вместе с site: или с и/или оператором
Если вы хотите найти несколько слов, то необходимо использовать скобки, тогда вы найдете все документы, в которых эти слова присутствуют, например
title:(подбор персонала IT)
Но у этого оператора есть ограничение – ранжирование будет производиться не по релевантности заголовков: вы просто получите те документы, в заголовках которых встречается это слово или несколько слов.
Морфология поиска
В добавок к операторам, которые помогают искать по документам, существуют контекстные ограничения и морфология, которые также полезны при исследовании результатов поиска.
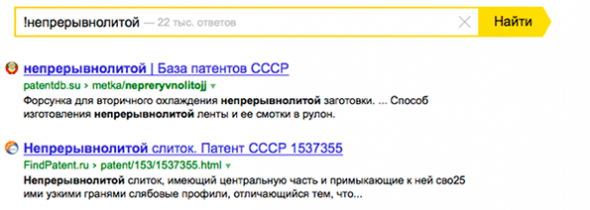
Если вы хотите оценить или сформировать ЧПУ (что не всегда оказывается легкой задачей, если ваш запрос относится к специфическим понятиям или сложным сочетаниям (технология непрерывнолитой заготовки)
!непрерывнолитой
Поможет оценить вхождения для разных ЧПУ и выбрать оптимальный вариант. В примере удачные ЧПУ выделены поисковиком:
Исследование контекстных ограничений
Путеводитель/(+1+1) купить
Этот запрос значит, что слова должны встречаться в заданном порядке, то есть вам важно расстояние между словами.
~~ исключение слова
Слово минус слово. Это исключит все лишние документы:

Кавычки (“”)
ищут цитаты или документы содержащие слова в заданной форме и последовательности. Зачем это нужно?
- поможет определить чистые вхождения и естественность словоформы
- проверить текст на уникальность
- найти дубли в рамках заданного сайта
- поможет найти НПС
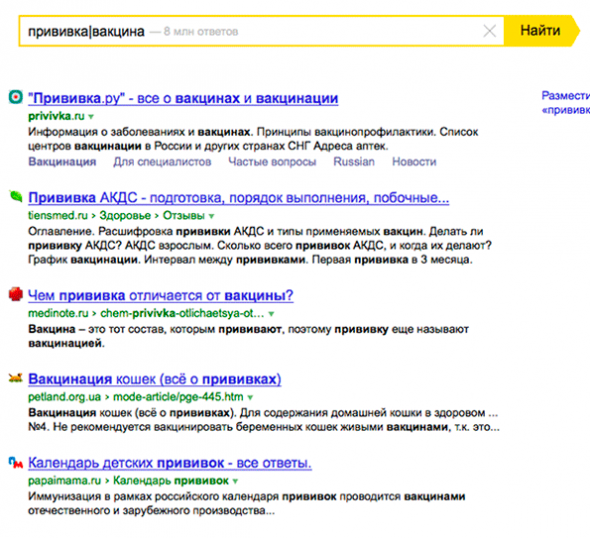
и | или
полезен для сравнения запросов. Можно заставить систему искать сайты релевантные по одному запросу или по другому, а потом система смешает выдачу по двум запросам, исходя из текущего значения релевантности. Так можно сравнивать конкурентность запросов.
Параметры поисковой строки
Кроме поисковых операторов, мы можем воспользоваться другими способами оформить cвои пожелания к Яндексу, а именно, мы можем сделать дополнение к браузерной строке:
&rd=0
Показывает все результаты поиска, снимает фильтр на одинаковые сниппеты
&how=tm
Сортирует результаты поисковой выдачи по новизне, а не по релевантности. Это очень удобно, когда нужно определить наиболее новые или старые документы на заданном сайте, то есть при совместном использовании с url можно посмотреть индексацию и дату заданного документа. Этот параметр также заменяем поисковым оператором date.
FQA по операторам в Google
site:
ищет результаты в пределах заданного хоста идентично оператору host: в Яндексе.
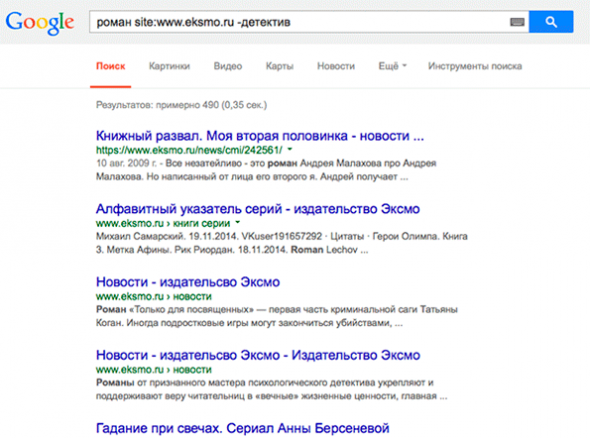
- (минус)
Исключить из результатов лишние слова можно с помощью оператора минус «-». В отличие от двойной тильды Яндекса, этот оператор не исключит полностью документы, которые содержат лишнее слово, но отберет для вас те результаты, в которых оно не присутствует в одно фразе с искомым:
allintitle:
также как и в Яндексе осуществляет поиск по заголовкам
OR слово ИЛИ слово
Аналогично яндексовскому «|»
””
Уже знакомые по Яндексу кавычки
Уникальные операторы, которых нет в Яндексе
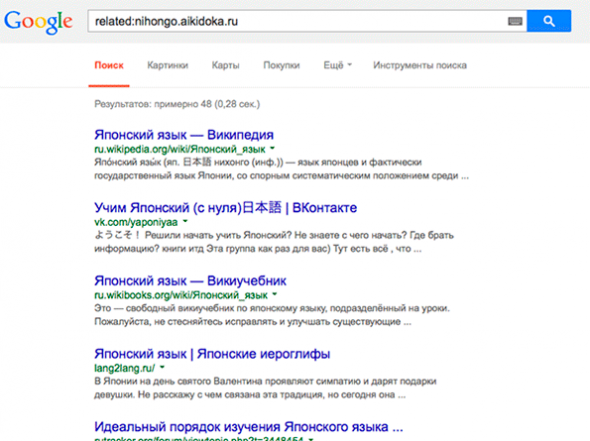
related:site.ru
То есть можно ввести url вашего сайта и проверить будут ли выдаваться сайты прямых конкурентов – если нет, возможно тематика сайта не очень хорошо определена.
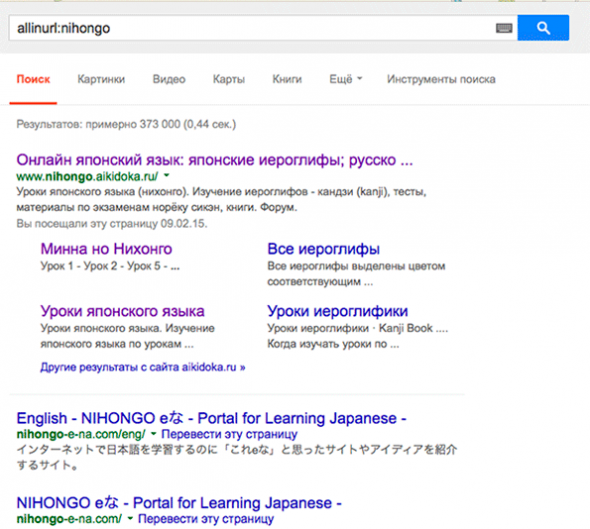
allinurl:
если использовать этот оператор, поиск ограничится теми сайтами, url которых содержит указанные слова
inanchor:
если использовать этот оператор, то вы сможете увидеть страницы, на которые есть ссылки с используемым ключевым словом.
Сравнение дополнительного индекса и основного
Все прекрасно знают, что в Google есть основной индекс и дополнительный. Страницы из дополнительного индекса скрываются в результатах поиска и не выдаются пользователям по запросам:
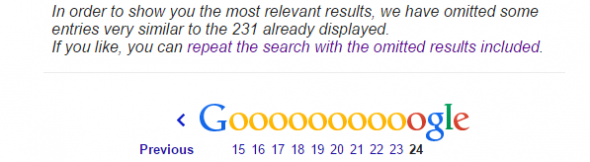
С помощью уже известного всем оператора site: и адреса сайта можно увидеть все страницы, которые находятся в общем индексе, а при добавлении & к урлу сайта мы с вами увидим только основной индекс:
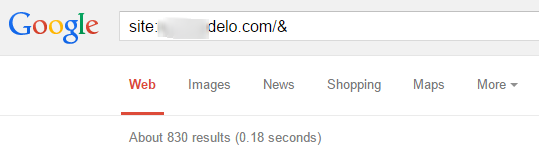
Эти данные также доступны в дополнениях и плагинах для браузеров (в том же RDS bar), но при ручном вводе вы можете увидеть те самые страницы или кластер страниц, которые Google считает не качественными и не пускает в основной индекс.