В этой статье вы найдете быстрый и эффективный способ собрать семантику для одной страницы всего за пару минут. Пошаговая и понятная инструкция для начинающих seo-специалистов.
Все seo-специалисты прекрасно знают, что без семантики в продвижении сайта не обойтись. Ведь она представляет собой базу ключевых слов, и именно на их основе в дальнейшем создается контент сайта, от которого зависит ранжирование.
Чаще всего семантику собирают на этапе планирования структуры для наполнения сайта контентом. Такой процесс называется сбором семантического ядра. Однако бывают ситуации, когда сайт уже давно запущен, основной контент размещен, но в один прекрасный момент вы решаете добавить новую страницу. Где в таком случае взять для нее семантику?

Рис.1. Где взять семантику
Тогда на помощь приходит поверхностный сбор.
В чем его плюсы?
- Точечный выбор подходящей под страницу семантики.
- Небольшие затраты по времени.
- Легкость и простота процесса.
Однако также стоит учитывать следующее: поскольку эта задача делается вручную, есть шансы упустить нужные запросы. Поэтому крайне важно быть внимательным!
В данной статье мы покажем, как можно легко и быстро сделать поверхностный сбор семантики.
Что нам потребуется
Предлагаем вам ознакомиться с основными определениями, которые могут встретиться в процессе чтения, и программами, необходимыми для сбора семантики.
Термины:
- Коммерческие запросы — направлены на совершение покупки товара/услуги. Характеризуются словами: «цена», «стоимость», «купить», «заказать», «доставка» и так далее. Также полезно знать, что коммерческие запросы являются частью более широкого понятия — транзакционные запросы, которые характеризуют совершение конкретного конверсионного действия (примеры: «купить», «скачать», «читать» и т.д.).
- Информационные запросы — используются при поиске какой-либо информации. Могут начинаться со слов: «как», «зачем», «сколько», «почему», «что такое» и т.п. Также могут включать слова: «характеристика», «отзывы», «инструкция», «описание» и т.д.
- Частотность — характеризует то, сколько раз пользователи вводили в поисковой системе данный запрос.
- Базовая частота — количество упоминаний исследуемого словосочетания в других запросах.
- Частота «!» (уточненная) — количество запросов исследуемого словосочетания именно в той форме, в которой оно написано.
Также в процессе поверхностного сбора семантики нам понадобятся:
1. Расширение для Yandex.Wordstat — «Yandex Wordstat Helper»

Рис.2. Yandex Wordstat Helper
Программа Key Collector (в данной статье используется версия 3.7)
Любые другие сервисы, которые помогут с подбором синонимов.
Помимо этого, мы упоминаем в статье такой показатель, как KEI. В Key Collector для этого показателя можно ввести любую нужную вам формулу, чтобы рассчитать тот или иной коэффициент. Мы используем формулу: отношение базовой частоты к уточненной. И если данное значение у запроса превышает 25, то для дальнейшей работы мы его не берем.
И если вы захотите использовать наш метод, то в настройках Key Collector нужно будет ввести следующую формулу: KEI=YandexWordstatBaseFreq / YandexWordstatQuotePointFreq
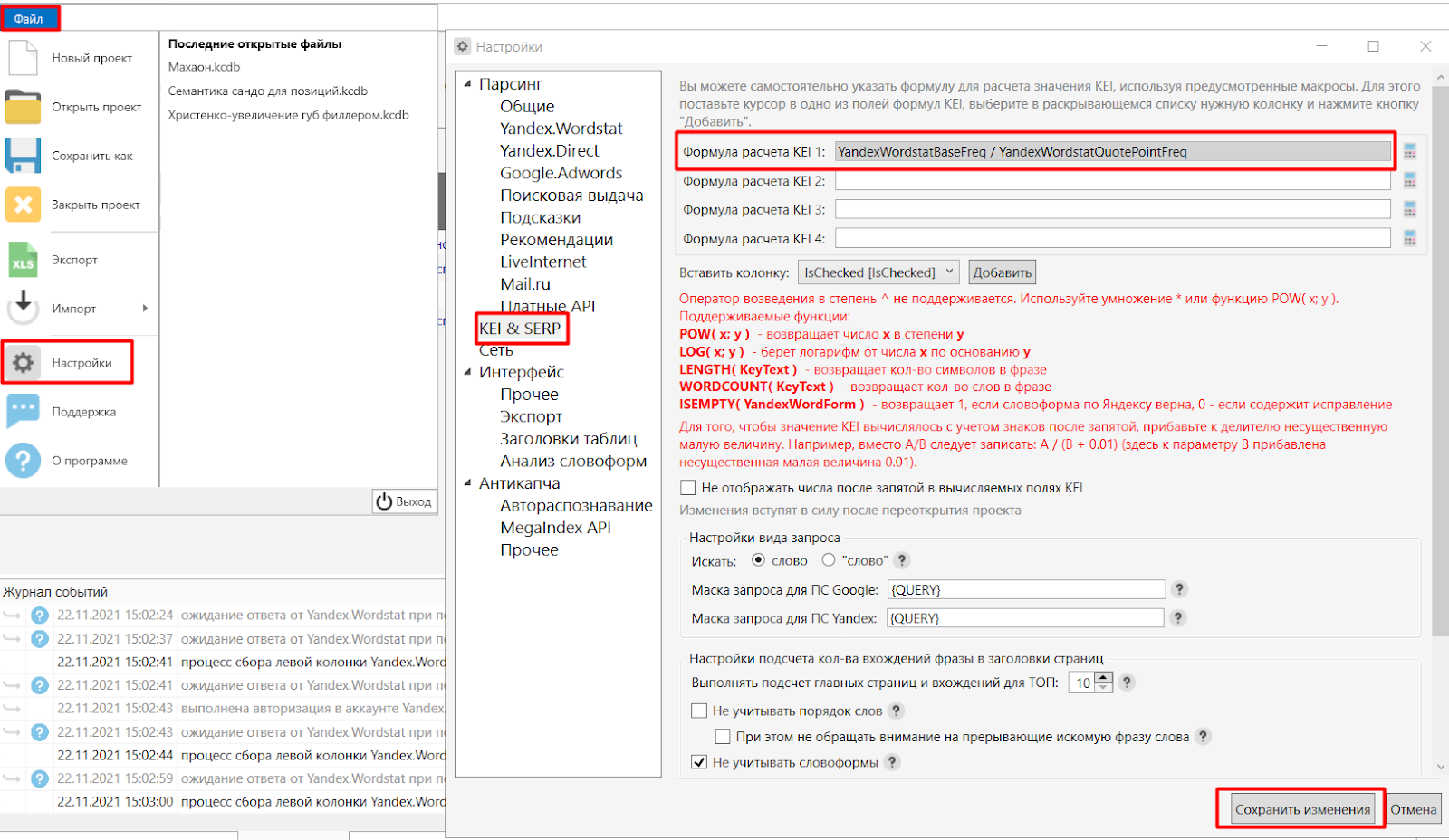
Рис.3. Вводим формулу в настройках Key Collector
Почему это круто: реальный пример
Хотим показать вам реальный пример того, как отработало внедрение семантики, собранной поверхностным способом.
Мы ввели семантику в работу на нескольких страницах в начале лета. И на графике вы можете наблюдать, как подросли позиции в течение последних 3-х месяцев. Особенно хорошо подтянулись позиции в топ-10, хотя и остальные хуже не стали.

Рис.4. Отчет видимости из сервиса SeoWork
Да, есть некоторые провалы, но они несущественны в общей тенденции на повышение. И не будем забывать, что на изменение позиций страниц сайта в поисковой системе влияние оказывает не только семантика, но и огромное количество различных факторов ранжирования. Поэтому нужно понимать, что поверхностный сбор семантики и ее дальнейшее внедрение — это определенно очень классно и полезно, но про остальные факторы также не стоит забывать.
Инструкция по применению
Перейдем к рассказу о том, как же устроен весь этот процесс. Для этого поделим его на несколько этапов.
Выясняем запрос
Для поверхностного сбора семантики нам нужно в первую очередь определить, с каким именно запросом предстоит работать и на какую тему собирать семантику.
Если изначально была дана страница, для которой нужно собрать семантику, то следующим шагом будет анализ данной страницы.
Для этого:
- заходим на страницу;
- смотрим, какой именно товар/услуга предлагается (для уточнения можно посмотреть фото);
- проверяем URL страницы.
Например, необходимо подобрать запрос под страницу прямые кухни на заказ

Рис.5. Изучаем страницу и ее URL — https://www.1mf.ru/vse-kukhni/pryamye-kukhni/
Теперь мы видим, что нам нужны именно прямые кухни, а не линейные или, например, п-образные.
Также по данной странице мы можем заметить, что у нас нет никакой привязки ни к цвету, ни к размеру, поэтому эти характеристики в дальнейшем мы использовать не будем.
Но следует сразу разобраться, к какому типу относится запрос: к коммерческому или информационному (если не помните разницы, смотрите термины в начале статьи).
В данном случае это страница каталога, целью которой является продать прямую кухню, а значит, запрос будет коммерческим.
Подбираем запросы с Яндекс.Вордстат
Как мы упоминали выше, перед началом работы необходимо установить Yandex Wordstat Helper. Он позволяет быстро и удобно собирать подходящие запросы.

Рис.6. Устанавливаем Yandex Wordstat Helper
Также следует помнить: поиск запросов производится только по определенному региону (в зависимости от сайта, с которым работаем на данный момент).
Почему так? Все достаточно просто. Согласитесь, если вы, например, продаете услуги пластического хирурга в Москве, то вряд ли вас будет интересовать спрос на эти услуги в Норильске. Поэтому нам не нужно ориентироваться на данные регионов, в которых мы свои услуги и товары продвигать не собираемся.
Но возвращаемся к работе с кухнями. Что нужно делать дальше:
- Вводим нужный запрос.
- Выбираем нужный регион (в данном случае Санкт-Петербург).
- Начинаем собирать запросы с помощью Yandex Wordstat Helper (нажимаем «+„, тогда все выбранные запросы переместятся в окошко слева, откуда будет удобно их скопировать).
- Запросы, у которых есть предлоги, следует писать через знак “+» (например, +в спб +на заказ).
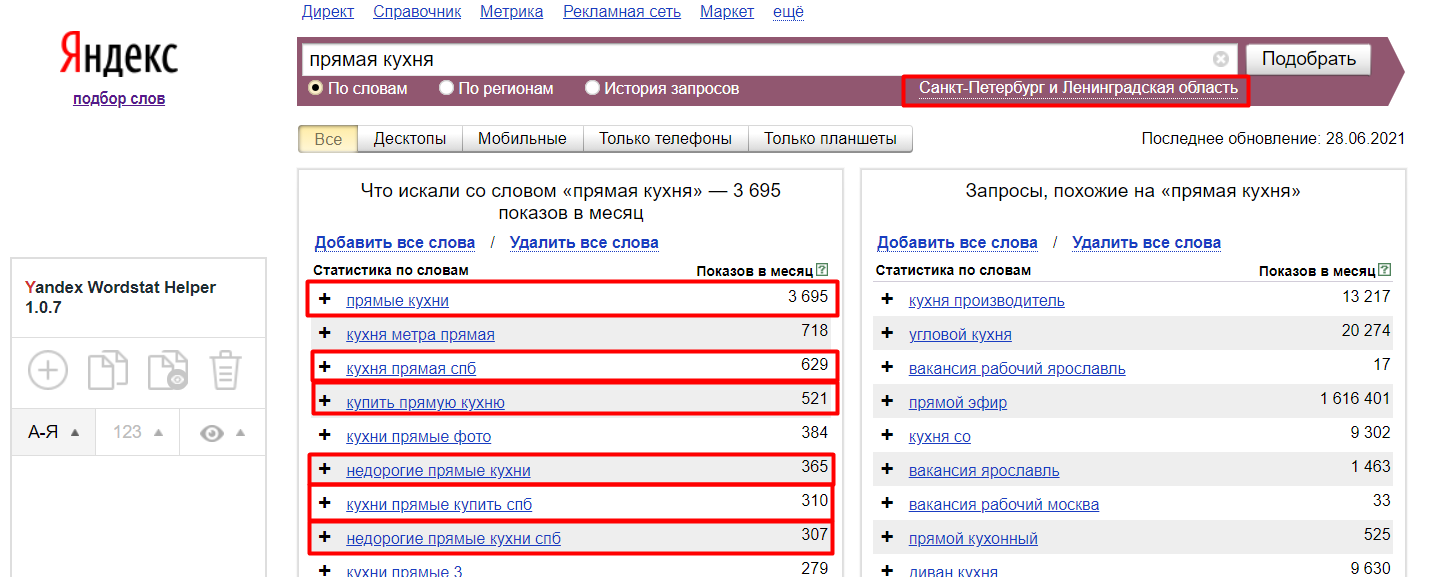
Рис.7. Вводим запрос
В Вордстате существует ряд функций, которые помогут ускорить процесс поиска подходящей семантики и сократить количество запросов.
1. Удаление неподходящих запросов, в которых указаны ненужные слова: «-слово -слово». Слово можно указывать в любом склонении.
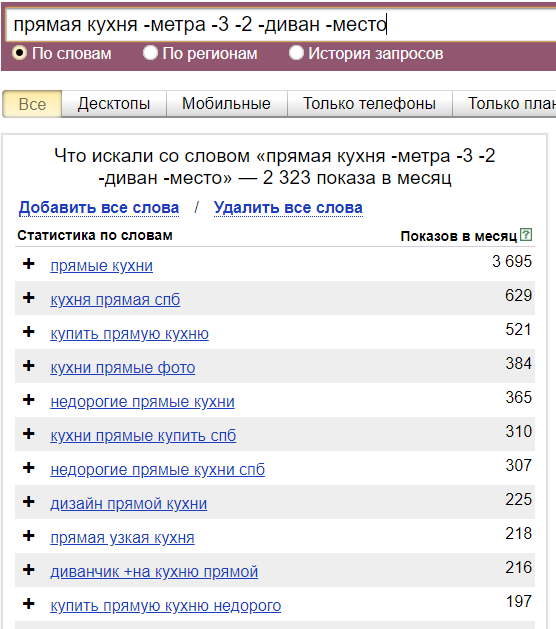
Рис.8. Удаляем неподходящие запросы
Выбрать слова, которые необходимо удалить с помощью данной функции, можно за счет анализа выданных запросов (например, слово «фото» характеризует инфозапрос, а слово «диван» не подходит по тематике).
2. Чтобы выводились только коммерческие запросы, стоит добавить слова-маркеры: (купить|цена|стоимость|стоить|недорого|дешево|заказ|заказать), можно добавить другие подходящие слова.
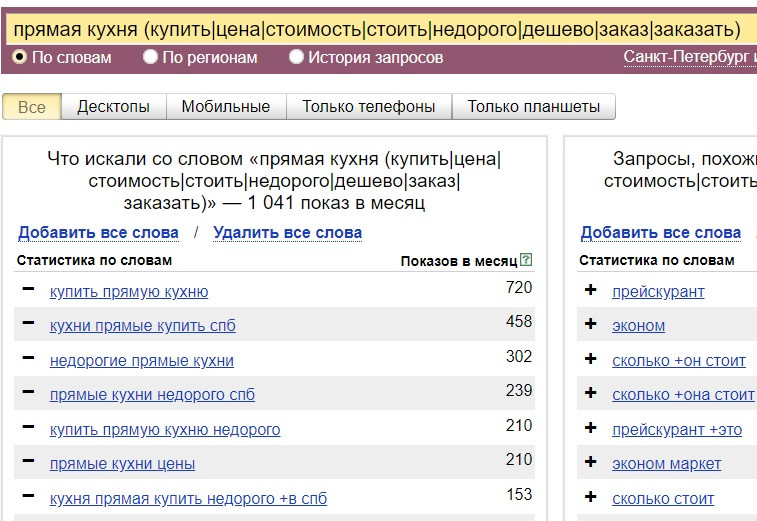
Рис.9. Добавляем слова-маркеры
3. Чтобы получить конкретную фразу в запросе, необходимо заключить ее в кавычки: «купить зеленую кухню +в спб» (форма слов в таком запросе будет меняться).

Рис.10. Заключаем фразу в кавычки
4. Чтобы формы слов не изменялись, нужно перед каждым словом в запросе поставить восклицательный знак: «!купить !зеленую !кухню +в !москве».
Важно! Для того чтобы собрать более полную семантику, вместо основного запроса необходимо также подставлять синонимы. Например, в основном запросе «купить шторы» слово «шторы» можно заменить на «портьеры» и на «занавески».
Подбирать синонимы нужно в обязательном порядке, поскольку без них можно упустить огромный пласт семантики и в итоге некачественно оптимизировать страницу. Например, если тематика сайта медицинская, то мы можем рассматривать как обычные запросы, так и медицинские термины: пластика носа + ринопластика, пластика груди + маммопластика и т.д.

Рис.11. Мем про синонимы
Таким образом, подбирая различные словосочетания и синонимы, можно собрать достаточный объем семантики для анализируемой страницы.
Переходим в Key Collector
Теперь, когда мы собрали всю возможную семантику по нужной нам теме, продолжаем работать с ней в Key Collector. Почему нельзя остановиться на предыдущем этапе? Потому что некоторые из собранных нами запросов могут не иметь уточненной частотности или могут принадлежать не одному кластеру. В процессе прочтения данной статьи вы поймете, о чем идет речь.
Теперь нам необходимо скопировать выбранные запросы и загрузить их в программу Key Collector.
Сначала нужно будет создать новый проект. Для собственного удобства назовите его четко и понятно, чтобы в дальнейшем избежать путаницы :-)
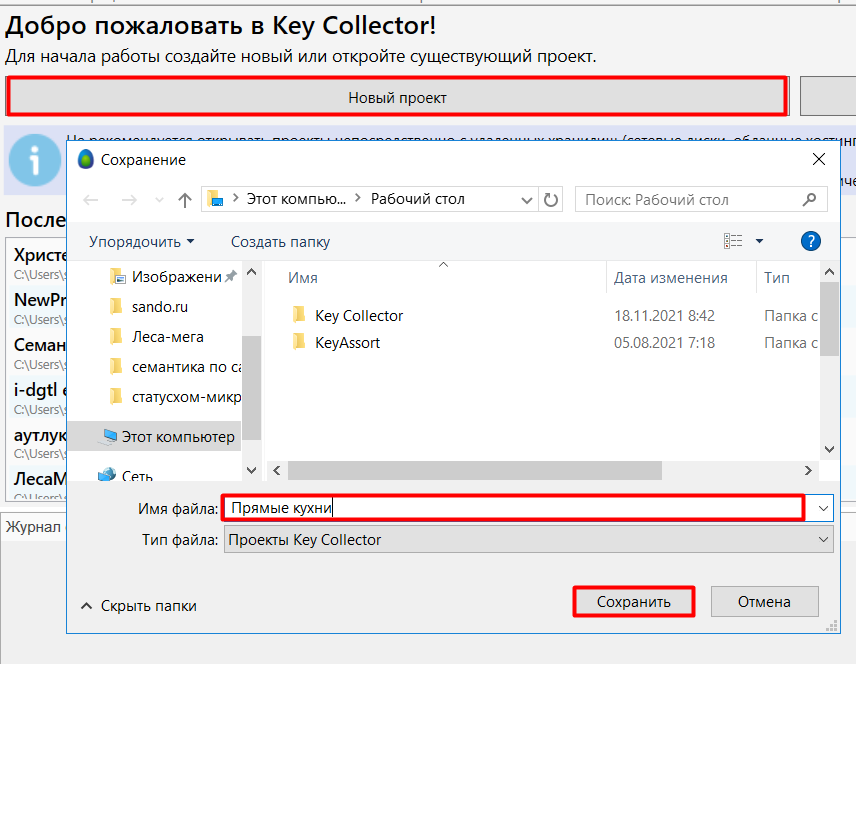
Рис.12. Создаем новый проект
Теперь, когда проект создан, нужно добавить скопированные запросы.
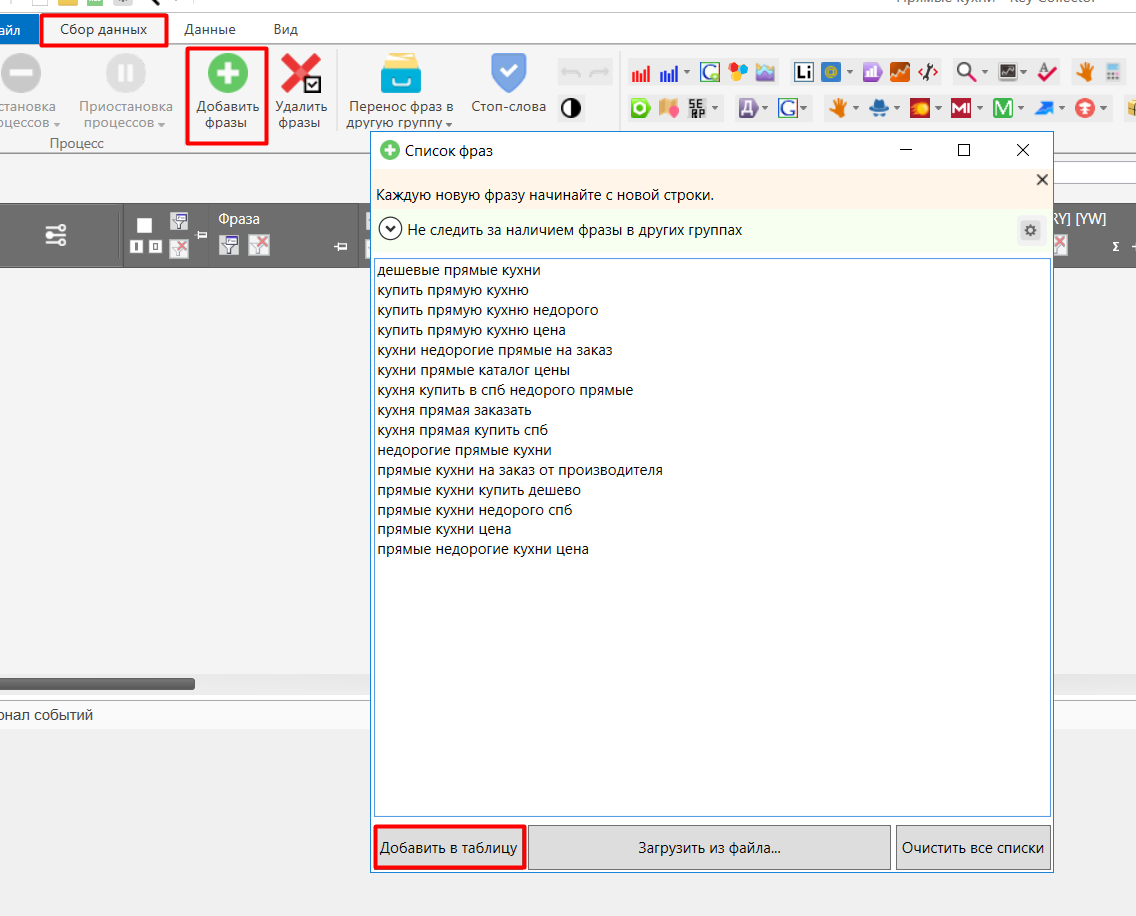
Рис.13. Добавляем запросы
Для того чтобы собрать частотность по добавленной семантике, необходимо настроить программу:
Выбрать нужный регион (в данном случае Санкт-Петербург) в нижней части окна.

Рис.14. Добавляем регион
Настроить функцию по сбору частотности.
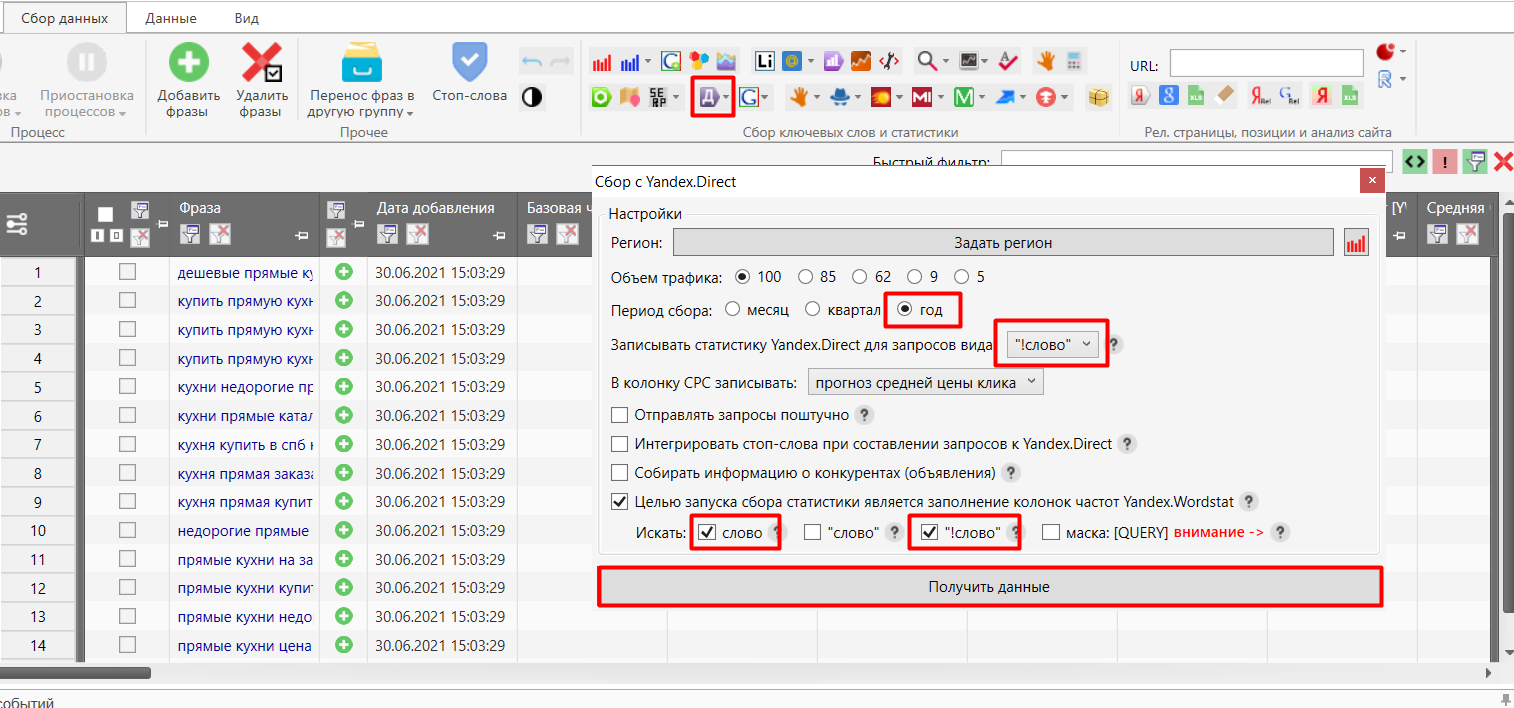
Рис.15. Настраиваем функцию по сбору частотности
Нас интересуют столбцы «Базовая частота» и «Частота »!"". Эти понятия описаны в начале статьи.
После сбора частотности можно нажать на название колонки и упорядочить "по убыванию"/"по возрастанию".
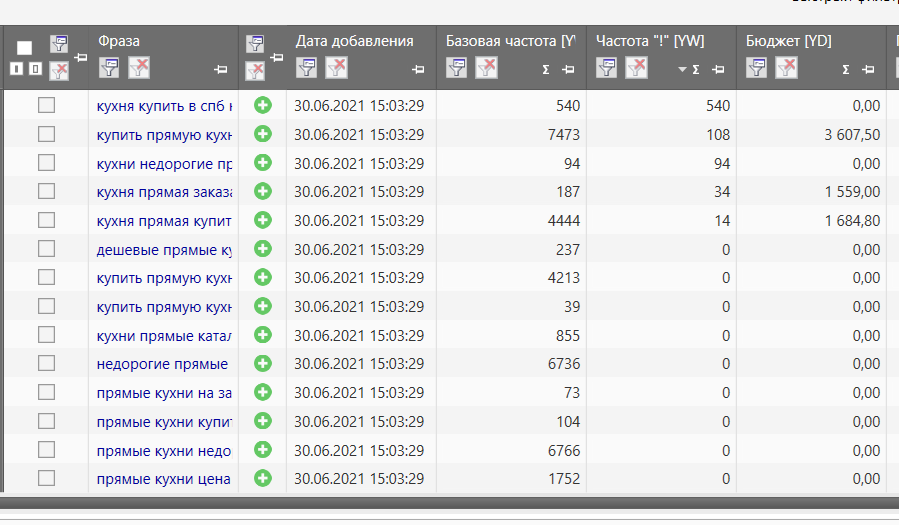
Рис.16. Список "по убыванию"/"по возрастанию"
Важно! Нулевые запросы в продвижении страницы мы не используем. Тут все ясно: нам не нужно продвигать страницу по запросам, на которые нет спроса. Поэтому нужно удалить все нулевые запросы как по базовой частоте, так и по уточненной.
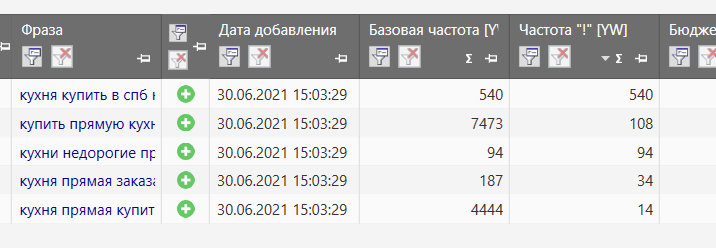
Рис.17. Удаляем все нулевые запросы
Теперь нужно рассчитать коэффициент KEI. Запросы, у которых KEI больше 25, необходимо удалить.
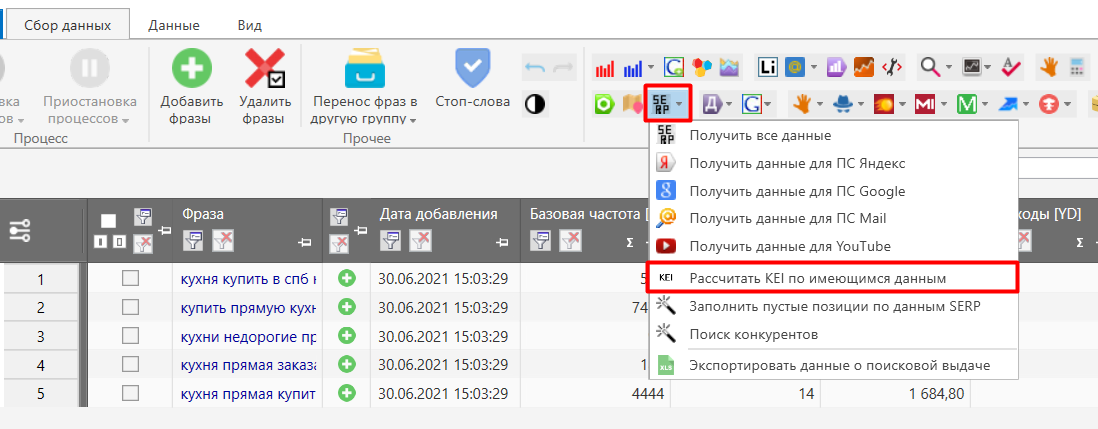
Рис.18. Удаляем запросы, у которых KEI больше 25
Если после расчета коэффициент не появляется в таблице, можно нажать кнопку «Автонастройка видимости колонок».

Рис.19. Автонастройка видимости колонок
Теперь нужно посмотреть позиции сайта. То есть мы анализируем, ранжируется ли наш сайт в поисковой выдаче по полученным нами запросам.
Для этого мы вставляем URL анализируемого сайта, как указано на скрине, и нажимаем на значок Яндекса.

Рис.20. Вставляем URL анализируемого сайта
Благодаря этому, мы можем увидеть, находится ли наш сайт в топ-10 по данным запросам, какие места он занимает и правильная ли страница ранжируется.
Если страница занимает 5-10 места, мы можем сделать вывод, что менять/дорабатывать текст на данной странице не нужно, поскольку мы и так занимаем хорошие позиции. При изменении текста есть риск их потерять, если сделать что-то неправильно.
Также бывают ситуации, когда по определенному запросу ранжируется неподходящая страница. Например, если по запросу «кухня прямая заказать» будет ранжироваться страница, продающая зеленые деревянные кухни, то это будет тревожный звоночек, который скажет нам, что пора разобраться с семантикой и на других страницах.

Рис.21. Мем про то, когда по определенному запросу ранжируется неподходящая страница
Кластеризуем
Далее нам необходимо проверить, являются ли данные запросы частями одного кластера (группы). Это можно сделать благодаря инструменту arsenkin.ru.
Кластеризуем запросы, чтобы распределить их по тематическим группам, собрать в эту группу как можно больше подходящих запросов и иметь больше возможностей для продвижения данной страницы. Кроме того, это поможет очистить нашу семантику от мусора, если процессе сбора к нам случайно затесался совершенно нерелевантный запрос.
Итак, что мы делаем:
- Вставляем наши запросы.
- Выбираем поисковую систему.
- Выбираем регион (обязательно!).
- Нажимаем «Начать проверку».

Рис.22. Кластеризация
Инструмент выдает нам информацию о конкурентах, которые по данным запросам занимают позиции в топ-10. И чтобы разделить разные кластеры, необходимо, чтобы у всех запросов было не менее 3-х общих конкурентов.
Если у какого-то запроса менее 3-х общих конкурентов, мы понимаем, что данный запрос из другого кластера и не будем брать его в работу.

Рис.23. Ищем общих конкурентов
Когда запросы отобраны и кластеризованы, мы получаем готовый кластер для анализируемой страницы. На этом процесс поверхностного сбора семантики закончен. Теперь ее можно передавать в дальнейшую работу.
Заключение
Может показаться, что это достаточно объемный и длительный процесс. Но проделав его всего пару раз, вы доведете его до автоматизма и сможете быстро и качественно собирать семантику.
Надеемся, что данная статья была вам полезна.
А если вам удобнее воспринимать информацию на слух, то рекомендуем посмотреть наши видео-уроки по этой теме: теоретическую часть и практическую. Также в описании теоретического урока вы сможете найти тест, который поможет вам понять, насколько хорошо вы усвоили данный материал.
Автор: Варвара Михальцова ( Ant-team.ru).